Chess
Program that learns to play chess via reinforcement learning (Tensorflow).
Chess v1.0.3
Overview
Tensorflow program that learns to play chess via Reinforcement Learning. Check out the demo!
Description
This program learns to play chess via reinforcement learning. The action-value functions are learned by training a neural network on the total return of randomly-initialized board states, determined by Monte Carlo simulations. The program follows an epsilon-greedy policy based on the most current action-value function approximations. As of v1.0.1, each training step is trained on batches of full-depth Monte Carlo simulations. The model architecture has two hidden layers, though this can be easily expanded or even updated to a convolutional architecture (to be included in a future release).
The game’s basic rules are encoded in pieces.py and the board state parameters are defined in state.py. Once a proper action-value function is converged upon, it can be implemented with a greedy policy for purposes of gameplay. The program test_bench.py is included for validating trained model performance against a benchmark policy.
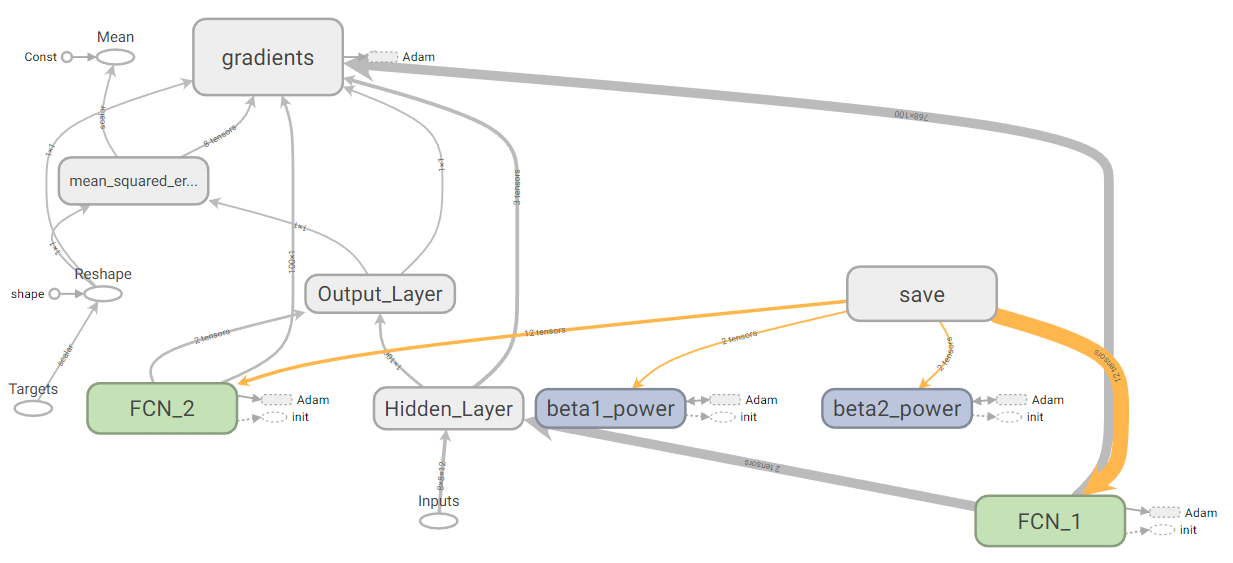
To Run
- Install Tensorflow [1]
- Set user-defined parameters in command line. ```shell usage: main.py [-h] [-t TRAINSTEPS] [-u HIDUNITS] [-r LEARNRATE] [-b BATCHSIZE] [-m MAXMOVES] [-e EPSILON] [-v VISUALIZE] [-p PRINT] [-a ALGEBRAIC] [-l LOADFILE] [-rd ROOTDIR] [-sd SAVEDIR] [-ld LOADDIR]
optional arguments: -h, –help show this help message and exit -t TRAINSTEPS, –trainsteps TRAINSTEPS Number of training steps (Default 1000) -u HIDUNITS, –hidunits HIDUNITS Number of hidden units (Default 100) -r LEARNRATE, –learnrate LEARNRATE Learning rate (Default 0.001) -b BATCHSIZE, –batchsize BATCHSIZE Batch size (Default 32) -m MAXMOVES, –maxmoves MAXMOVES Maximum moves for MC simulations (Default 100) -e EPSILON, –epsilon EPSILON Epsilon-greedy policy evaluation (Default 0.2) -v VISUALIZE, –visualize VISUALIZE Visualize game board? (Default False) -p PRINT, –print PRINT Print moves? (Default False) -a ALGEBRAIC, –algebraic ALGEBRAIC Print moves in algebraic notation? (Default False) -l LOADFILE, –loadfile LOADFILE Load model from saved checkpoint? (Default False) -rd ROOTDIR, –rootdir ROOTDIR Root directory for project -sd SAVEDIR, –savedir SAVEDIR Save directory for project -ld LOADDIR, –loaddir LOADDIR Load directory for project ```
- Run main.py. (2)
- (Optional) Run Tensorboard to visualize learning. (3)
- (Optional) Run test_bench.py to compare model performance against a benchmark. At the current time, the benchmark is a random policy, however future releases will allow the user to load other benchmark models. (4)
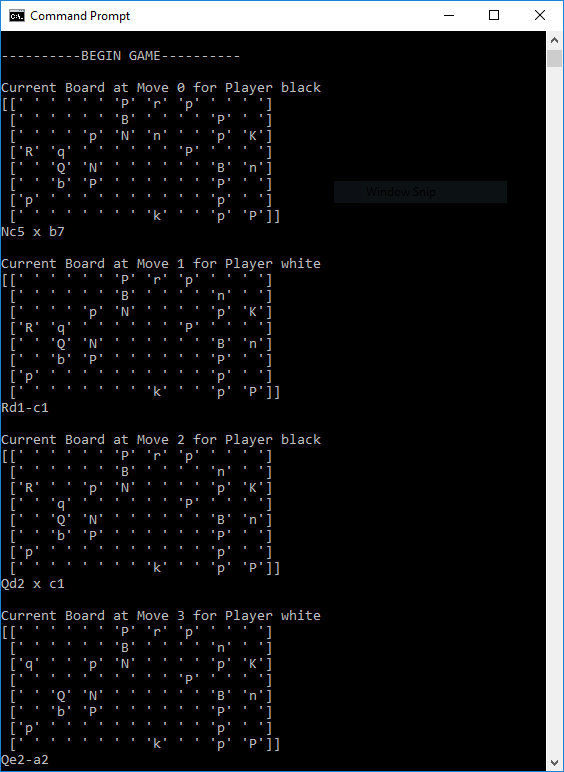
The following is a sample output for data visualization in the terminal or command prompt:
Update Log
v1.0.3: Added argparse support for command-line program initiation.
v1.0.2: Included support for game visualization and move printing in chess or longhand notation.
v1.0.1: Bug fixes and support for large training batches. Added test bench program for analysis.
v1.0.0: Beta version.
Notes
(1) This program was built on Python 3.6 and Tensorflow 1.5.
(2) The terminal display includes the current step, training loss, percent completion, and time remaining. Training games may be visualized based on user-defined settings above. The current model is saved at each time step.
(3) Upon completion of training, training loss at each step is written to an output .txt file for analysis.
(4) This program outputs training progress and mean outcome in the terminal (where outcomes are -1 for loss, 0 for draw, 1 for win). This information is saved to an output .txt file for subsequent statistical analysis. Testing games may be visualized based on user-defined settings above.